
Avatar: The Last Airbender
A TidyTuesday project modelling Avatar TV show scripts.
Today we are looking at text data from the scripts for the TV show ‘Avatar: The Last Airbender’.
I decided to see if certain characters that dominate a show, based on their word count, affects the ratings in a postive or negative way. It would be interesting to incorporate screen time as well, but all I have here is word count.
Setup
First we setup our enivronment and load the dataset.
library(tidytuesdayR)
library(tidyverse)## ── Attaching packages ────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.1 ✓ dplyr 1.0.0
## ✓ tidyr 1.1.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ───────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(knitr)
library(kableExtra)##
## Attaching package: 'kableExtra'## The following object is masked from 'package:dplyr':
##
## group_rowsknitr::opts_chunk$set(
echo = TRUE,
fig.height = 5,
fig.width = 8,
message = FALSE,
warning = FALSE,
dpi = 180
)Load the data
avatar <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-08-11/avatar.csv')Data Manipulation and Cleanup
Next we create dataframes to capture the text data for all characters, the totals per episode, then join them.
word_counts <- avatar %>%
filter(character != "Scene Description") %>% # removes non-character speaking text
select(book, book_num, chapter_num, character, character_words, imdb_rating) %>%
mutate(word_counts = str_count(character_words)) %>%
group_by(book_num, chapter_num, character) %>%
summarise(word_counts = sum(word_counts),
rating = mean(imdb_rating)) %>%
ungroup()
word_totals <- word_counts %>%
group_by(book_num, chapter_num) %>%
summarise(total_words = sum(word_counts)) %>%
ungroup()
df <- word_counts %>%
left_join(word_totals) %>%
mutate(word_perc = word_counts / total_words) %>%
arrange(book_num, chapter_num, -word_perc)Create list of top 6 characters by word count. We will only plot these characters as they have the most words compared to the other characters.
top_chars <- df %>%
group_by(character) %>%
summarise(char_word_counts = sum(word_counts)) %>%
arrange(desc(char_word_counts)) %>%
top_n(6, char_word_counts) %>%
pull(character)Below is a first crack. I create a scatter plot and then use stat_ellipse to get a rough idea of the distribution and centroid for each character. Each point is an episode. I ignore which book/season of the series is involved, but it might be interesting to see how character’s evolve over the arc of the entire series.
df %>%
filter(character %in% top_chars) %>%
ggplot(aes(rating, word_perc)) +
geom_point() +
stat_ellipse() +
facet_wrap(~ character)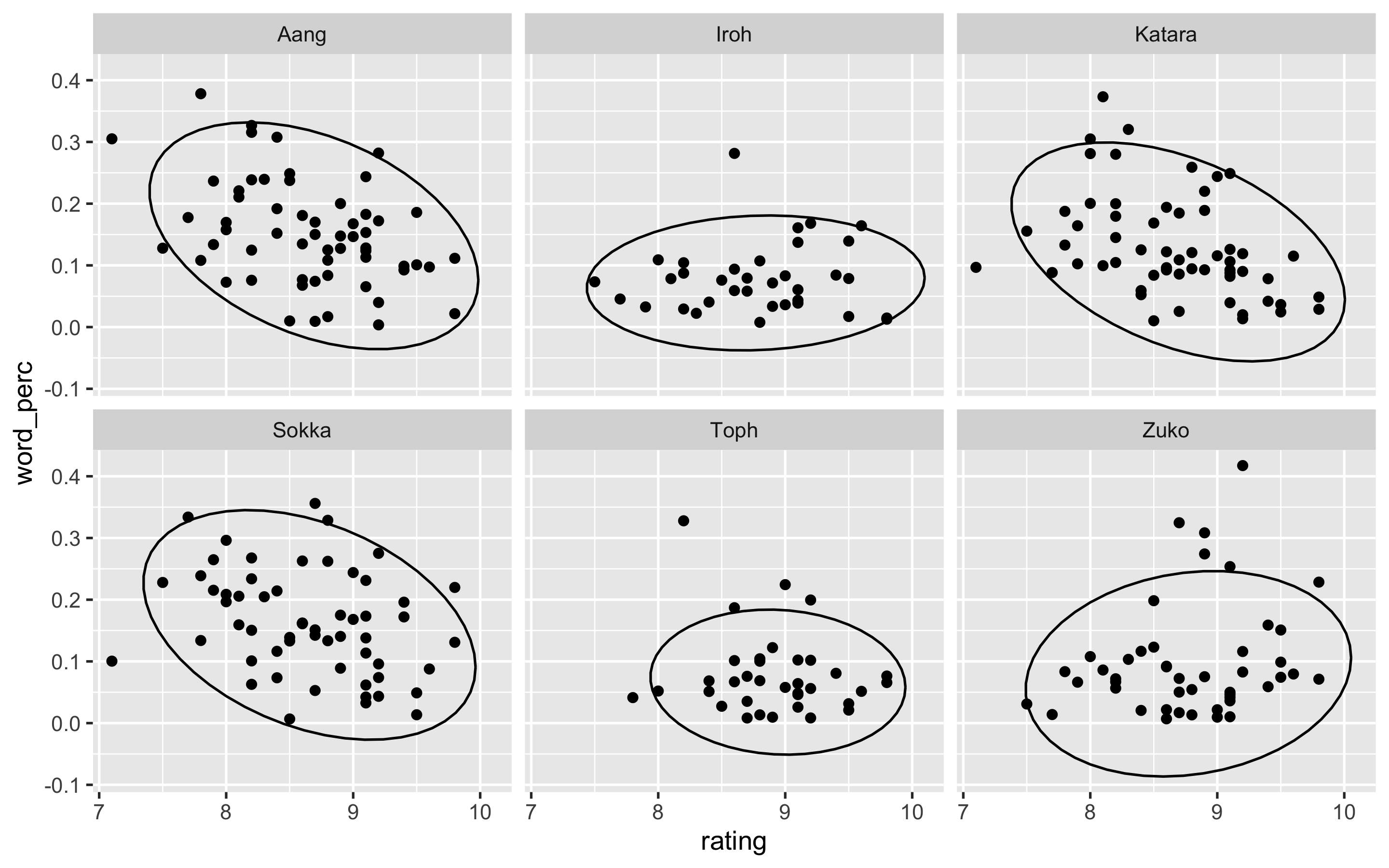
Now let’s make the plot pretty.
Notice we can use the group.colors named list to dictate who gets assigned which color. Neat!
library(ggtext)
group.colors <- c(Sokka = "#1C3F6E", Aang = "#EFFC93", Katara = "#0F2347", Iroh = "#a10000", Zuko = "#a10000", Toph = "#80C271")
p <- df %>%
filter(character %in% top_chars) %>%
ggplot(aes(rating, word_perc)) +
geom_point(aes(color = character), alpha = 1, show.legend = FALSE) +
stat_density_2d(alpha = .2, show.legend = FALSE) +
scale_color_manual(values = group.colors) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
facet_wrap(~ character) +
theme_minimal() +
labs(
x = "IMDB Rating",
y = "",
title = "<span style='color:#a10000'>**Zuko**</span>-heavy Episodes Maintain High Ratings",
subtitle = "Character Word Count / Total Word Count Per Each Episode",
caption = "Joseph Pope | @joepope44"
) +
theme(
text = element_text(family = "Verdana"),
panel.background = element_rect(fill = "lightgrey"),
panel.grid = element_blank(),
plot.title = element_markdown(size = 20),
strip.text = element_text(face = "bold")
)
p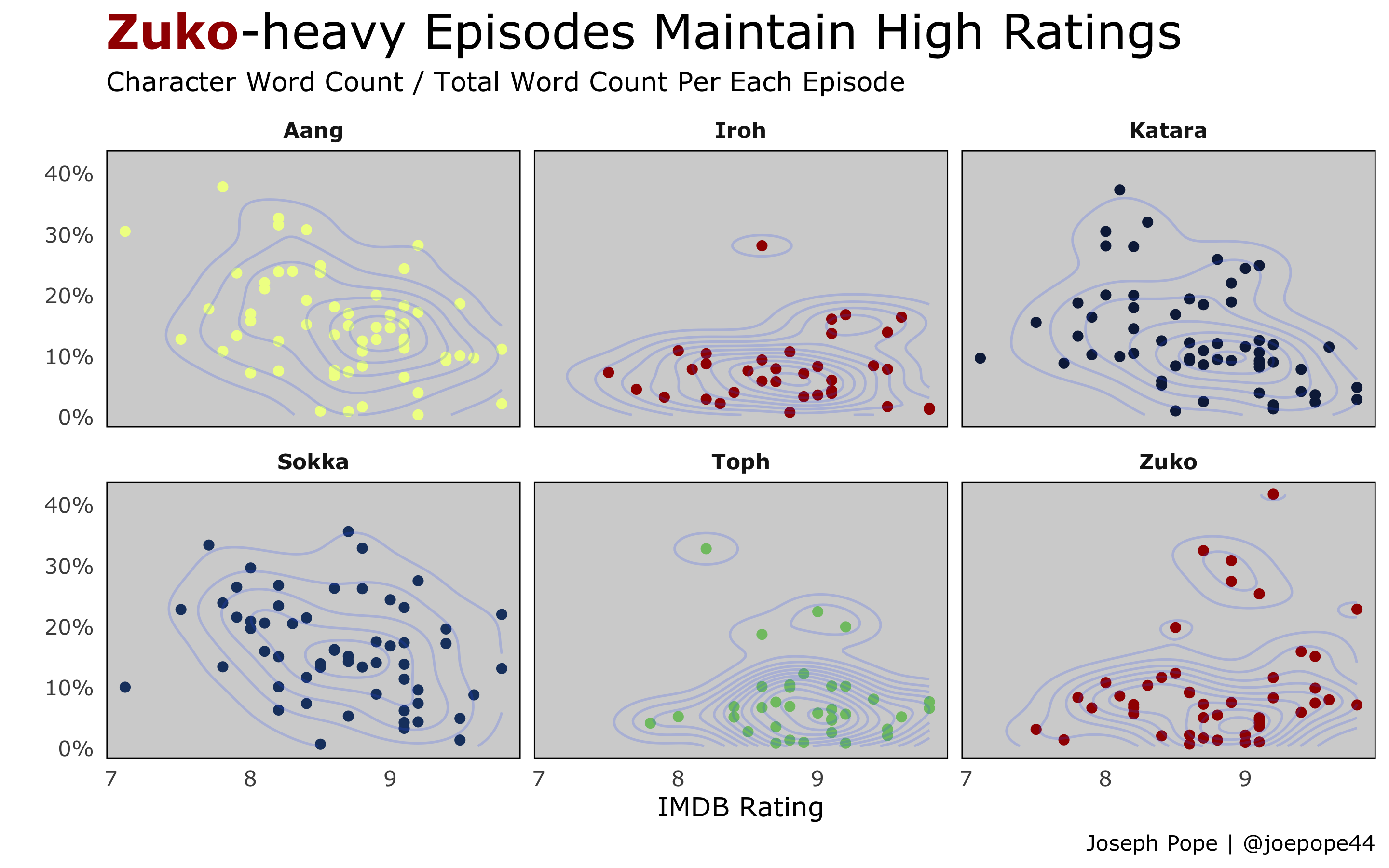
I use a density 2D plot to help show how the points are distributed.
I don’t think this came out quite as informative as I would have liked, but it is interesting to see that Zuko has several episodes where he is speaking the most out of all characters, and those all appear to have relatively high ratings.

